Tjek trykfejlslisten for evt. fejl eller registrerede problemer siden publiceringen.
Dokumentet er også tilgængeligt i følgende non-normative format: Japanesk oversættelse
Copyright © 2003-2014 W3C® (MIT, ERCIM, Keio, Beihang), Alle rettigheder forbeholdt. W3C’s regler for hæftelse, varemærke og dokumentanvendelse er gældende.
Hensigten med denne introduktion er at give læseren det grundlæggende kendskab, der er nødvendigt for at bruge RDF effektivt. Den præsenterer de grundlæggende begreber i RDF og giver konkrete eksempler på brugen af RDF. Afsnit 3-5 kan bruges som en minimumsintroduktion til nøgleelementerne i RDF. Forskelle mellem RDF 1.1 og RDF 1.0 (2004-versionen) er sammenfattet i et særskilt dokument: ”What's New in RDF 1.1” [RDF11-NEW].
Dette afsnit beskriver den aktuelle dokumentstatus på tidspunktet for publiceringen. Andre dokumenter vil muligvis gøre dette dokument overflødigt. En liste over aktuelle W3C-publikationer, samt den seneste revision af denne tekniske rapport, kan findes i W3C technical reports index på http://www.w3.org/TR/.
Dokumentet her er en del af RDF 1.1-dokumentationen. Det er en informativ fortegnelse over nøglebegreber i RDF. En normativ beskrivelse af RDF 1.1 findes i dokumentet RDF 1.1. Concepts and Abstract Syntax document [RDF11-CONCEPTS]. Dette dokument indeholder mindre redaktionelle rettelser af versionen fra februar 2014.
Dokumentet her blev publiceret af RDF Working Group som et arbejdsgruppenotat. Kommentarer og bemærkninger til dette dokument kan sendes til public-rdf-comments@w3.org (subscribe, archives). Alle kommentarer er velkomne.
Offentliggørelse af et arbejdsgruppenotat forudsætter ikke godkendelse af W3C-medlemskabet. Dokumentet er et udkast og kan til hver en tid opdateres, udskiftes eller overflødiggøres af andre dokumenter. Det er uhensigtsmæssigt at omtale dette dokument som andet end et igangværende projekt.
Dokumentet her blev fremlagt af en gruppe, der arbejder under 5 February 2004 W3C Patent Policy. W3C fører en offentlig liste over enhver patentanmeldelse, der er foretaget i forbindelse med gruppens publikationer. Siden omfatter også vejledning i at anmelde et patent. Enkeltpersoner med konkret viden om et patent, som vedkommende mener indeholder væsentlige fordringer, skal fremlægge oplysningerne i henhold til afsnit 6 i W3C Patent Policy.
RDF (Resource Description Framework) er en ramme beregnet til at udtrykke informationer om ressourcer. Ressourcer kan være hvad som helst, f.eks. dokumenter, personer, fysiske genstande og abstrakte begreber.
RDF er beregnet på situationer, hvor informationer på internettet skal behandles af programmer frem for blot at blive vist for mennesker. RDF er en fælles struktur, der kan udtrykke disse informationer, så de kan udveksles mellem programmer uden at miste deres betydning. Eftersom det er en fælles struktur, kan programudviklere drage nytte af de tilgængelige, fælles RDF-parsere og databehandlingsværktøjer. Muligheden for at udveksle information mellem forskellige programmer betyder, at informationerne kan gøres tilgængelige for andre end de programmer, informationerne oprindeligt var beregnet på.
RDF kan især bruges til at publicere og sammenkæde data på internettet.
Adressen http://www.example.org/bob#me
kan f.eks. indeholde data om Bob, herunder at han kender Alice, der kan
identificeres af sin IRI (en IRI er en ”international ressourceidentifikation”.
Yderligere oplysninger se afsnit. 3.2).
Ved at åbne Alices IRI kan man så finde flere data om hende, herunder links til
andre datasæt om hendes venner, interesser mv. En person eller en automatiseret
proces kan derpå følge sådanne forbindelser og indsamle data om disse forskellige
ting. Den slags brug af RDF kan ofte kvalificeres som Linked Data [LINKED-DATA].
Dokumentet her er ikke normativt og indeholder derfor ikke en komplet beskrivelse af RDF 1.1. RDF’s normative specifikationer kan findes i følgende dokumenter:
Det følgende belyser forskellige anvendelser af RDF og er rettet mod forskellige praksisfællesskaber.
Med RDF kan man fremsætte udsagn om ressourcer. Disse udsagn har et simpelt format. Et udsagn har altid følgende opbygning:
<subjekt> <prædikat> <objekt>
Et RDF-udsagn udtrykker forholdet mellem to ressourcer. Subjektet og objektet repræsenterer to ressourcer, der bliver knyttet til hinanden. Prædikat repræsenter forholdets beskaffenhed. Forholdet er formuleret på en retningsbestemt måde (fra subjekt til objekt) og kaldes en egenskab i RDF. Eftersom RDF-udsagn består af tre elementer, kaldes de tripler.
Følgende er eksempler på RDF-tripler (uformelt udtrykt i pseudokode):
<Bob> <er en> <person>.
<Bob> <er ven med> <Alice>.
<Bob> <er født> < 4. juli 1990>.
<Bob> <er interesseret i> <Mona Lisa>.
<Mona Lisa> <blev malet af> <Leonardo da Vinci>.
<Videoen 'La Joconde à Washington'> <handler om> <Mona Lisa>
Flere tripler henviser ofte til samme ressource. I ovenstående eksempel er Bob subjekt i fire tripler, mens Mona Lisa er subjekt i én og objekt i to tripler. Fordi ressourcer kan stå som subjekt i én tripel og objekt i en anden, er det muligt at finde forbindelser mellem tripler, hvilket er en vigtig styrke i RDF.
Man kan forestille sig tripler som en forbundet graf. Grafer består af knuder og kanter. En tripels subjekter og objekter udgør grafens knuder. Prædikaterne udgør kanterne. Fig. 1 viser den graf, der kan tegnes ud fra de ovenstående tripler.
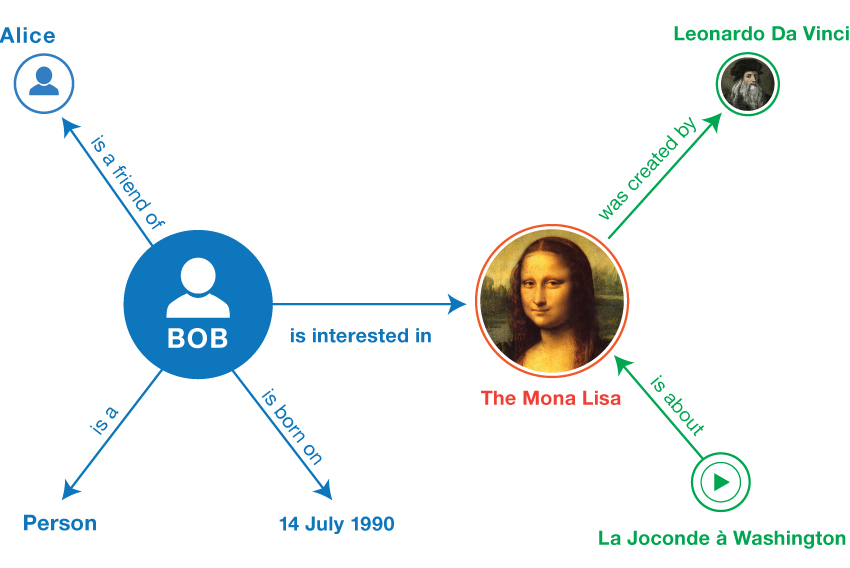
Når man først har sådan en graf, kan man bruge SPARQL [SPARQL11-OVERVIEW] til f.eks. at søge efter personer, der er interesseret i Leonardo da Vincis malerier.
RDF-datamodellen er i dette afsnit beskrevet med en ”abstrakt syntaks”, dvs. en datamodel, der er uafhængig af en bestemt konkret syntaks (den syntaks, som er brugt til at beskrive tripler gemt i tekstfiler). Forskellige konkrete syntakser kan resultere i præcis den samme graf fra den abstrakte syntaks’ perspektiv. RDF-grafers semantik [RDF11-MT] defineres af denne abstrakte syntaks. Konkret RDF-syntaks præsenteres i afsnit 5.
I de følgende tre underafsnit omtales de tre typer RDF-data, der findes i tripler: IRI’er, literaler og tomme knuder.
Forkortelsen IRI står for ”International Resource Identifier” – international ressourceidentifikation. En IRI identificerer en ressource. De URL’er (Uniform Resource Locators eller enhedsressourcefindere), man bruger som web-adresser, er en slags IRI’er. En anden type IRI identificerer en ressource uden at vise dens placering, og hvordan man kan tilgå den. Begrebet IRI er en generalisering af begrebet URI (Uniform Resource Identifier), så tegn uden ASCII-kode kan bruges i en IRI-tekststreng. IRI’er specificeret i RFC 3987 [RFC3987].
IRI’er kan stå på alle triplens tre positioner.
Som nævnt bruges IRI’er til at identificere ressourcer som dokumenter, personer, fysiske genstande og abstrakte begreber. I DBpedia er IRI’en for Leonardo da Vinci f.eks.:
I Europeana er IRI’en for en INA-video om Mona Lisa med titlen ”La Joconde à Washington”:
IRI’er er globale identifikatorer, så andre kan genbruge en bestemt IRI til at identificere den samme ting. Den følgende IRI bruges f.eks. af mange som RDF-egenskab til at udtrykke bekendtskabsforhold mellem folk:
RDF har intet kendskab til det, som IRI’erne repræsenterer. Men IRI’er kan
få en betydning ved hjælp af særlige vokabularier eller konventioner. DBpedia bruger f.eks. IRI’er
med formen http://dbpedia.org/resource/Name
til at angive det, som er beskrevet af den tilsvarende artikel i Wikipedia.
Literaler er grundværdier, som ikke er IRI’er. Eksempler på literaler kan være tekststrenge som ”La Joconde”, datoer som ”4. juli 1990” og tal som ”3.14159”. Literaler er knyttet til en datatype, hvorved sådanne værdier kan analyseres og fortolkes korrekt. Man kan vælge at knytte et sprogmærke til en tekststrengsliteral. ”Léonard de Vinci” kan f.eks. tilknyttes sprogmærket ”fr” og ”李奥纳多·达·文西” sprogmærket ”zh”.
Literaler kan kun findes på en tripels objektposition.
Dokumentet RDF Concepts indeholder en (ikke udtømmende) liste over datatyper. Dette omfatter mange datatyper, der er defineret af XML Schema, f.eks. string, boolean, integer, decimal og date.
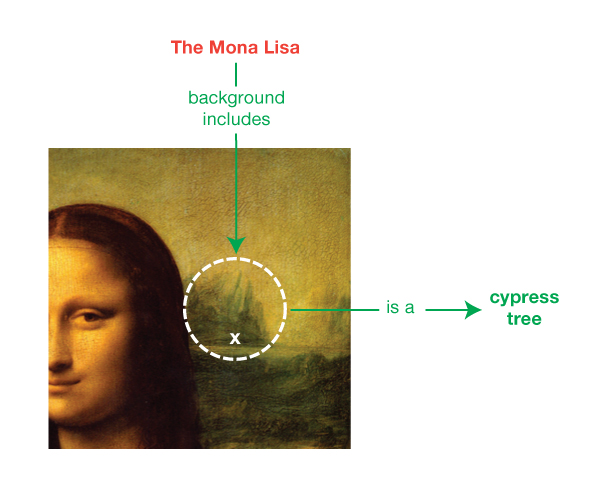
IRI’er og literaler udgør tilsammen de grundlæggende elementer til at skrive RDF-udsagn. Indimellem er det desuden praktisk at kunne tale om ressourcer uden at bekymre sig om at bruge en global identifikator. Vi vil måske udtrykke, at der i baggrunden af Mona Lisa-maleriet er et uidentificeret træ, som vi ved er en cypres. En ressource uden en global identifikator, f.eks. maleriets cypres, kan i RDF repræsenteres af en tom knude. Tomme knuder er som simple variable i algebra; de repræsenterer noget uden at angive en værdi.
Tomme knuder kan findes både på en tripels subjekt- og objektposition. De kan bruges til at betegne ressourcer uden eksplicit at navngive dem med en IRI.
RDF indeholder en mekanisme, så man kan kombinere RDF-udsagn i flere grafer og tilknytte en IRI til sådanne grafer. Sammensatte grafer er en nyere ekstension af RDF-datamodellen. I praksis havde RDF-udviklere og -arkitekter brug for en mekanisme, så de kunne tale om delmængder af en samling tripler. Sammensatte grafer blev først præsenteret i RDF-søgesproget SPARQL. RDF-datamodellen blev derfor udvidet med begrebet sammensatte grafer, det er tæt knyttet til SPARQL.
Sammensatte grafer i et RDF-dokument udgør et RDF-datasæt. Et RDF-datasæt kan have flere navngivne grafer og mindst én unavngiven (”standard-”) graf.
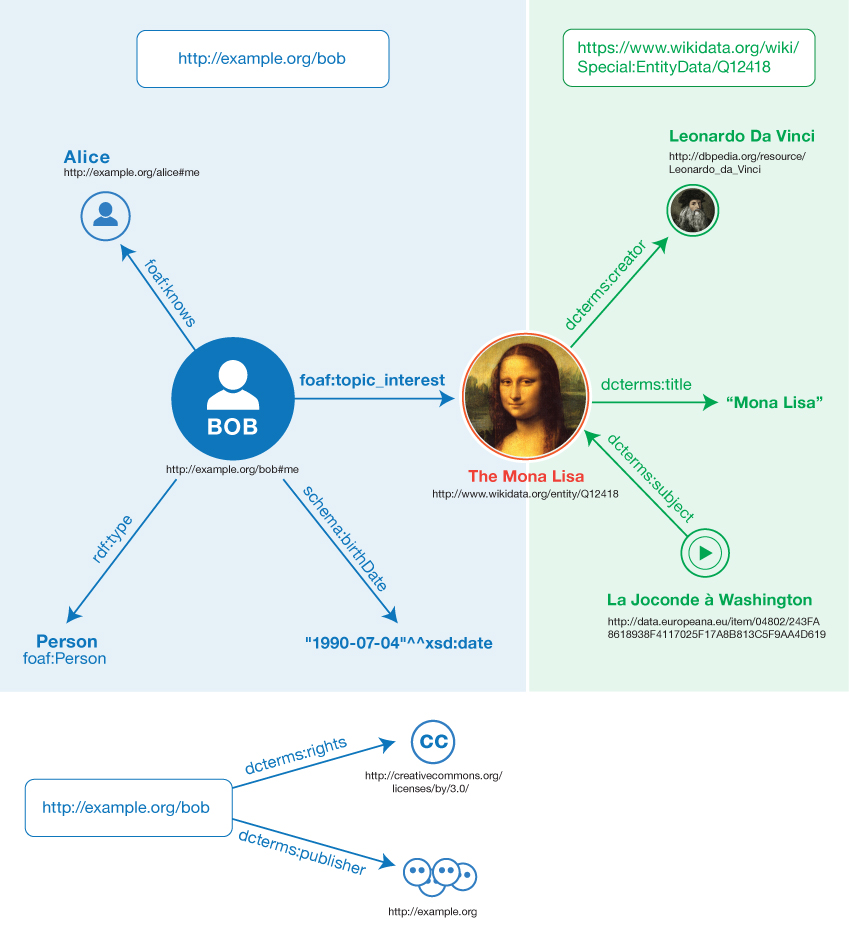
Udsagnene i eksempel 1
kunne f.eks. grupperes i to navngivne grafer. En første graf kunne komme fra et
socialt netværk og identificeres af http://example.org/bob:
<Bob> <er en> <person>.
<Bob> <er venner med> <Alice>.
<Bob> <er født> <den 4. juli 1990>.
<Bob> <er interesseret i> <Mona Lisa>.
Den IRI, der er knyttet til grafen, kaldes grafnavnet.
En anden graf kunne komme fra Wikidata
og være identificeret af https://www.wikidata.org/wiki/Special:EntityData/Q12418:
<Leonardo da Vinci> <er skaber af> <Mona Lisa>.<Videon 'La Joconde à Washington'> <handler om> <Mona Lisa>
Herunder findes et eksempel på en unavngivet graf. Den
indeholder to tripler med grafnavnet <http://example.org/bob> som subjekt. Triplerne knytter udgiver og licensinformation til
denne grafs IRI:
<http://example.org/bob> <er publiceret af> <http://example.org>.
<http://example.org/bob> <har licens> <http://creativecommons.org/licenses/by/3.0/>.
I dette eksempel antages det, at grafnavnene repræsenterer kilden til de
RDF-data, der er indeholdt i den tilsvarende graf, dvs. ved at hente <http://example.org/bob> frem
ville der opnås adgang til de fire tripler i den graf.
RDF har ingen standardmetode, der kan udtrykke denne semantiske formodning (dvs. at grafnavne repræsenterer kilden til RDF-dataene) for andre af datasættets læsere. Disse læsere må støtte sig til ekstern viden for at fortolke datasættet på den tilsigtede måde. Datasæts mulige semantik er beskrevet i en særskilt note [RDF11-DATASETS].
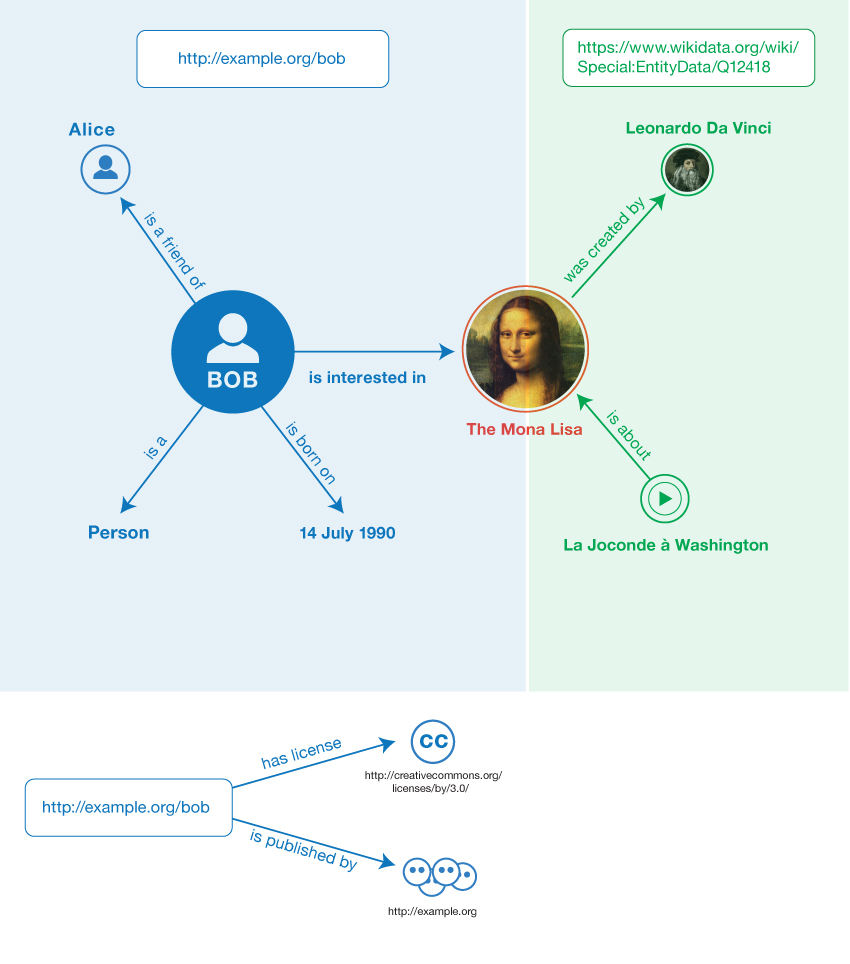
Fig. 3 skildrer ovenstående datasæt. Afsnit. 5.1.3 indeholder et eksempel på dette datasæts konkrete syntaks.
Med RDF-datamodellen kan man fremsætte udsagn om ressourcer. Som nævnt indeholder datamodellen ingen formodninger om, hvilken ressource IRI’erne står for. I praksis bruges RDF typisk i kombination med vokabularier eller andre konventioner, der indeholder semantisk information om disse ressourcer.
Til støtte for definitionen af vokabularier bruger RDF sproget RDF Schema [RDF11-SCHEMA].
Dette sprog gør det muligt at definere RDF-datas semantiske beskaffenhed. Man
kan f.eks. angive, at IRI’en http://www.example.org/friendOf
kan bruges som en egenskab, og at subjekterne og objekterne i triplen http://www.example.org/friendOf skal
være ressourcer af klassen http://www.example.org/Person.
RDF Schema bruger betegnelsen klasse for bestemte kategorier, som kan bruges til at klassificere ressourcer. Relationen mellem en forekomst og dens klasse udtrykkes gennem egenskaben type. Med RDF Schema kan man oprette hierarkier bestående af klasser og underklasser samt egenskaber og underegenskaber. Typerestriktioner på bestemte triplers subjekter og objekter kan defineres gennem restriktionerne domæne og rækkevidde. Ovenstående er et eksempel på en domænerestriktion: subjekter i”friendOf”-tripler bør tilhøre klassen ”Person”.
De væsentligste modelleringsbegreber i RDF Schema er sammenfattet i nedenstående tabel:
| Modelleringsbegreb | Syntaks | Beskrivelse |
|---|---|---|
| Klasse (en klasse) | C rdf:type rdfs:Class |
C (en ressource) er en RDF-klasse |
| Egenskab (en klasse) | P rdf:type rdf:Property |
P (en ressource) er en RDF-egenskab |
| type (en egenskab) | I rdf:type C |
I (en ressource) er en forekomst af C (en klasse) |
| underklasse af (en egenskab) | C1 rdfs:subClassOf C2 |
C1 (en klasse ) er en underklasse af C2 (en klasse) |
| underegenskab af (en egenskab) | P1 rdfs:subPropertyOf P2 |
P1 (en egenskab) er en underegenskab af P2 (en egenskab) |
| domæne (en egenskab) | P rdfs:domain C |
Domæne af of P (en egenskab) er C (en klasse) |
| rækkevidde (en egenskab) | P rdfs:range C |
Rækkevidde af P (en egenskab) er C (en klasse) |
Syntaksen (anden kolonne) er skrevet i en præfiksnotation,
der omtales yderligere i afsnit. 5.
At modelleringsbegreberne har to forskellige præfikser (rdf: og rdfs:) er et noget irriterende historisk levn, som er
bibeholdt af hensyn til den bagudrettede kompatibilitet.
Ved hjælp af RDF Schema kan man bygge en model af RDF-data. Et simpelt, uformelt eksempel:
<person> <type> <klasse> <er ved med> <type> <egenskab> <er ved med> <domain> <person> <er ved med> <range> <person> <er gode vennner med > <underegenskab af> <er ved af>
Bemærk, at selv om <er ven med>
er en egenskab, der typisk bruges som prædikat til en tripel (som i eksempel 1), er
egenskaber som disse i sig selv ressourcer, der kan beskrives af tripler eller
føje værdier til beskrivelser af andre ressourcer. I dette eksempel <er ven med> subjekt i tripler,
der føjer type-, domæne- og rækkeviddeværdier til det, og det er objekt i en
tripel, der beskriver noget om egenskaben <er gode venner med>.
Et af de første RDF-vokabularier, der blev brugt på verdensplan, var vokabulariet ”Friend of a Friend” (FOAF) til at beskrive sociale netværk. Andre eksempler på RDF-vokabularier er:
Værdien af vokabularier øges af genbrug. Jo mere disse IRI-vokabularier genbruges af andre, jo mere værdifuldt bliver det at bruge IRI’erne (den såkaldte netværkseffekt). Dette betyder, at man bør foretrække at genbruge andres IRI’er frem for at opfinde en ny.
Yderligere formel beskrivelse af modelleringsbegreberne i RDF Schema kan findes i ”RDF Semantics document” [RDF11-MT]. Ønsker man en mere omfattende semantisk modellering af RDF-data, kan man overveje at bruge OWL [OWL2-OVERVIEW]. OWL er et RDF-vokabularium, så det kan bruges sammen med RDF Schema.
Der findes et antal forskellige serialiseringsformater til at nedskrive RDF-grafer med. Men forskellige måder at nedskrive den samme graf fører til nøjagtig de samme tripler, og de er derfor logisk ækvivalente.
I dette afsnit præsenteres – med kommenterede eksempler – følgende formater:
Bemærk
Tip til læseren: Afsnit 5.1 (Turtle et al.) diskuterer alle grundlæggende begreber til serialisering af RDF. Det anbefales kun at læse afsnittene om JSON-LD, RDFa og RDF/XML, hvis der er interesse for denne særlige brug af RDF.
I dette underafsnit præsenterer vi fire RDF-sprog, som er nært beslægtede. Vi begynder med N-triples, som udgør den grundlæggende syntaks til at nedskrive RDF-tripler. Turtle-syntaksen udbygger denne grundlæggende syntaks med forskellige former for syntaktiske forbedringer, der øger læsbarheden. Derefter diskuterer vi TriG og N-Quads, der er ekstensioner af henholdsvis Turtle og N-triples og beregnet til at indkode sammensatte grafer. Tilsammen omtales disse fire som ” RDF-sprog af Turtle-typen”.
N-triples [N-TRIPLES] er en simpel, linjebaseret måde at serialisere RDF-grafer med almindelig tekst. Den uformelle graf i fig. 1 kan beskrives i N-triples på følgende måde:
01 <http://example.org/bob#me> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person> . 02 <http://example.org/bob#me> <http://xmlns.com/foaf/0.1/knows> <http://example.org/alice#me> . 03 <http://example.org/bob#me> <http://schema.org/birthDate> "1990-07-04"^^<http://www.w3.org/2001/XMLSchema#date> . 04 <http://example.org/bob#me> <http://xmlns.com/foaf/0.1/topic_interest> <http://www.wikidata.org/entity/Q12418> . 05 <http://www.wikidata.org/entity/Q12418> <http://purl.org/dc/terms/title> "Mona Lisa" . 06 <http://www.wikidata.org/entity/Q12418> <http://purl.org/dc/terms/creator> <http://dbpedia.org/resource/Leonardo_da_Vinci> . 07 <http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619> <http://purl.org/dc/terms/subject> <http://www.wikidata.org/entity/Q12418> .
Hver linje repræsenterer en tripel. Komplette IRI’er er omgivet af vinkler (<>). Mellemrummet for enden af
linjen signalerer afslutningen på triplen. I linje 3 er der et eksempel på en
literal – i dette tilfælde en dato. Datatypen er vedhæftet literalen ved hjælp
af skilletegnet ^^.
Datoformatet følger konventionerne for datatypen date i XML Schema.
Strengliteraler findes overalt, og derfor tillader N-triples, at brugeren
udelader datatypen, når der skrives en strengliteral. Derfor svarer "Mona Lisa" i linje 5 til "Mona Lisa"^^xsd:string. I
tilfælde af strenge med sprogmærke vises mærket direkte efter strengen, adskilt
af @-symbolet. F.eks "La Joconde"@fr (det franske navn for Mona Lisa).
Af tekniske årsager er datatypen for strenge med sprogmærke
ikke xsd:string, men rdf:langString. Datatypen for strenge
med sprogmærke angives aldrig eksplicit.
Nedenstående figur viser de tripler, der er resultatet af eksemplet:
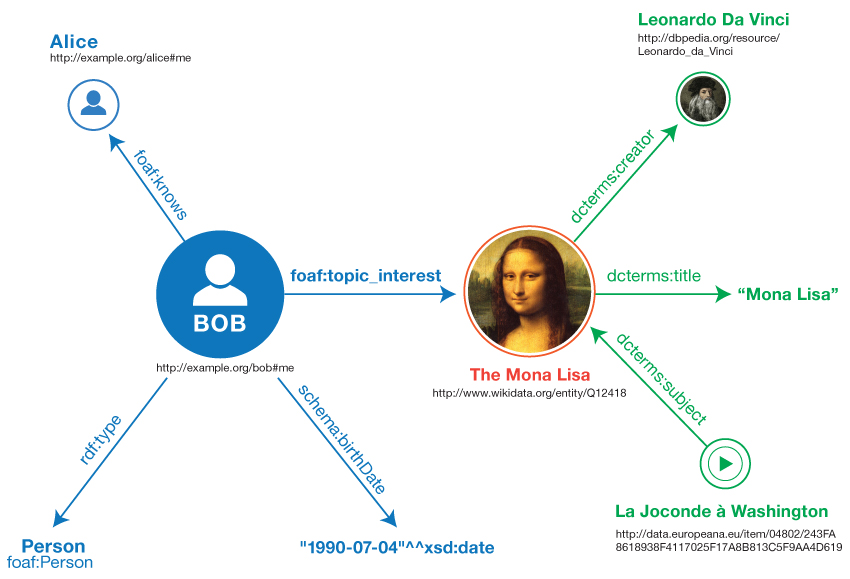
Bemærk, at de syv linjer i eksemplet med N-triples svarer til de syv kanter i diagrammet overfor.
N-triples bruges ofte til at udveksle store mængder RDF’er og til at behandle store RDF-grafer med linjeorienterede tekstbehandlingsværktøjer.
Turtle [TURTLE] er en ekstension til N-triples. I tillæg til N-triples’ grundlæggende syntaks introducerer Turtle et antal syntaktiske genveje, f.eks. understøttelse af præfikser til navneområder, lister og forkortelser for datatypedefinerede literaler. Turtle leverer et kompromis mellem nemheden ved at skrive, nemheden ved at parse og læsbarheden. Grafen i fig. 4 kan repræsenteres i Turtle på følgende måde:
01 BASE <http://example.org/> 02 PREFIX foaf: <http://xmlns.com/foaf/0.1/> 03 PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> 04 PREFIX schema: <http://schema.org/> 05 PREFIX dcterms: <http://purl.org/dc/terms/> 06 PREFIX wd: <http://www.wikidata.org/entity/> 07 08 <bob#me> 09 a foaf:Person ; 10 foaf:knows <alice#me> ; 11 schema:birthDate "1990-07-04"^^xsd:date ; 12 foaf:topic_interest wd:Q12418 . 13 14 wd:Q12418 15 dcterms:title "Mona Lisa" ; 16 dcterms:creator <http://dbpedia.org/resource/Leonardo_da_Vinci> . 17 18 <http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619> 19 dcterms:subject wd:Q12418 .
Turtle-eksemplet er en logisk ækvivalent til eksemplet med N-triples.
Linje 1-6 indeholder et antal erklæringer, som er en slags forkortelser til at
nedskrive IRI’er. Relative IRI’er (f.eks. bob#me
i linje 8) bestemmes mod en basis-IRI, her angivet i linje 1. Line 2-6
definerer IRI-præfikser (f.eks. foaf:),
som kan bruges til navne med præfikser (f.eks. foaf:Person) i stedet for hele IRI’er. Den tilsvarende
IRI konstrueres ved at erstatte præfikset med dets tilsvarende IRI (i dette
eksempel står foaf:Person
for <http://xmlns.com/foaf/0.1/Person>).
Linje 8-12 viser, hvordan man med Turtle kan bruge forkortelser til et sæt
tripler med samme subjekt. Linje 9-12 angiver prædikat-objekt-delen af tripler,
der har <http://example.org/bob#me>
som subjekt. Semikolonerne i slutningen af linje 9-11 angiver, at det
efterfølgende prædikat-objekt-par er del af en ny tripel, der bruger det nyeste
subjekt, der er vist i dataene— i dette tilfælde bob#me.
Linje 9 giver et eksempel på en særlig slags syntaktisk forbedring. Triplen
bør uformelt læses som ”Bob (er) en person”. Prædikatet a er en forkortelse for egenskaben rdf:type, som modellerer
forekomstrelationen (se tabel 1).
Hensigten med forkortelsen a
er, at det skal passe til et menneskes intuitive forståelse af rdf:type.
Herunder ses to variationer af nedskrevne tomme knuder, baseret på eksemplet med cypressen tidligere.
PREFIX lio: <http://purl.org/net/lio#>
<http://dbpedia.org/resource/Mona_Lisa> lio:shows _:x ._:x a <http://dbpedia.org/resource/Cypress> .
Udtrykket _:x er en tom
knude. Den beskriver en unavngivet ressource i maleriet af Mona Lisa. Den
unavngivne ressource er en forekomst af klassen Cypress. Ovenstående eksempel viser den konkrete syntaks
for den uformelle graf i fig. 2.
Turtle har også en alternativ notation for tomme knuder, som ikke kræver en
syntaks som _:x:
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
# en ressource (tom knude) er interesseret i en anden ressource
# kaldet "Mona Lisa" malet af Leonardo da Vinci.
[] foaf:topic_interest [ dcterms:title "Mona Lisa" ; dcterms:creator <http://dbpedia.org/resource/Leonardo_da_Vinci> ] .
Kantede parenteser udtrykker her en tom knude. Prædikat-objekt-parrene mellem de kantede parenteser fortolkes som tripler med den tomme knude som subjekt. Linjer, der begynder med ”#” er kommentarer.
Yderligere oplysninger om syntaksen i Turtle, se [TURTLE].
Syntaksen i Turtle understøtter kun beskrivelse af enkeltgrafer uden mulighed for at ”navngive” dem. TriG [TRIG] er en ekstension af Turtle, der muliggør beskrivelse af sammensatte grafer i form af et RDF-datasæt.
I RDF 1.1 er ethvert legalt Turtle-dokument et legalt TriG-dokument. Det kan opfattes som ét sprog. Navnene Turtle og TriG bruges stadig af historiske årsager.
En version af vores eksempel med sammesatte grafer kan beskrives på følgende måde i TriG:
01 BASE <http://example.org/> 02 PREFIX foaf: <http://xmlns.com/foaf/0.1/> 03 PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> 04 PREFIX schema: <http://schema.org/> 05 PREFIX dcterms: <http://purl.org/dc/terms/> 06 PREFIX wd: <http://www.wikidata.org/entity/> 07 08 GRAPH <http://example.org/bob> 09 { 10 <bob#me> 11 a foaf:Person ; 12 foaf:knows <alice#me> ; 13 schema:birthDate "1990-07-04"^^xsd:date ; 14 foaf:topic_interest wd:Q12418 . 15 } 16 17 GRAPH <https://www.wikidata.org/wiki/Special:EntityData/Q12418> 18 { 19 wd:Q12418 20 dcterms:title "Mona Lisa" ; 21 dcterms:creator <http://dbpedia.org/resource/Leonardo_da_Vinci> . 22 23 <http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619> 24 dcterms:subject wd:Q12418 . 25 } 26 27 <http://example.org/bob> 28 dcterms:publisher <http://example.org> ; 29 dcterms:rights <http://creativecommons.org/licenses/by/3.0/> .
Dette RDF-datasæt indeholder to navngivne grafer. Linje 8 og 17 angiver
navnene på disse to grafer. Triplerne i den navngivne graf er placeret mellem
et par krøllede parenteser (linje 9-15 og 18-25). Man kan alternativt angive
nøgleordet GRAPH foran
grafens navn. Det kan gøre det nemmere at læse, men er hovedsageligt indført
som en tilpasning til SPARQL Update [SPARQL11-UPDATE].
Den syntaks, der anvendes til triplerne og til erklæringerne øverst, er tilpasset Turtle-syntaksen.
De to tripler, der er beskrevet i linje 27-29, tilhører ikke nogen navngivet graf. De danner tilsammen RDF-datasættets unavngivne ”standardgraf”.
Nedenstående figur viser de tripler, der fremkommer af dette eksempel.
N-Quads [N-QUADS] er en simpel ekstension af N-triples, der gør det muligt at udveksle RDF- datasæt. Med N-Quads kan man føje et fjerde element til en linje og registrere triplens graf-IRI, som er beskrevet i den linje. Nedenstående er N-Quads-versionen af TriG-eksemplet:
01 <http://example.org/bob#me> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://xmlns.com/foaf/0.1/Person> <http://example.org/bob> . 02 <http://example.org/bob#me> <http://xmlns.com/foaf/0.1/knows> <http://example.org/alice#me> <http://example.org/bob> . 03 <http://example.org/bob#me> <http://schema.org/birthDate> "1990-07-04"^^<http://www.w3.org/2001/XMLSchema#date> <http://example.org/bob> . 04 <http://example.org/bob#me> <http://xmlns.com/foaf/0.1/topic_interest> <http://www.wikidata.org/entity/Q12418> <http://example.org/bob> . 05 <http://www.wikidata.org/entity/Q12418> <http://purl.org/dc/terms/title> "Mona Lisa" <https://www.wikidata.org/wiki/Special:EntityData/Q12418> . 06 <http://www.wikidata.org/entity/Q12418> <http://purl.org/dc/terms/creator> <http://dbpedia.org/resource/Leonardo_da_Vinci> <https://www.wikidata.org/wiki/Special:EntityData/Q12418> . 07 <http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619> <http://purl.org/dc/terms/subject> <http://www.wikidata.org/entity/Q12418> <https://www.wikidata.org/wiki/Special:EntityData/Q12418> . 08 <http://example.org/bob> <http://purl.org/dc/terms/publisher> <http://example.org> . 09 <http://example.org/bob> <http://purl.org/dc/terms/rights> <http://creativecommons.org/licenses/by/3.0/> .
De ni linjer i N-Quads-eksemplet svarer til de ni kanter i fig. 5. Linje 1-7 repræsenterer quads, hvor det første element udgør graf-IRI’en. Den del af quad’en, der efterfølger graf-IRI’en, angiver udsagnets subjekt, prædikat og objekt. Syntaksen følger konventionerne for N-triples. Linje 8 og 9 repræsenterer udsagnene i den unavngivne (standard-) graf, som mangler et fjerde element og derfor udgør almindelige tripler.
Ligesom N-triples, bruges N-Quads typisk til udveksling af store RDF-datasæt og til at behandle RDF med linjebaserede tekstbehandlingsværktøjer.
JSON-LD [JSON-LD] føjer JSON-syntaks til RDF-grafer og -datasæt. JSON-LD kan bruges til at omdanne JSON-dokumenter til RDF med et minimum af ændringer. JSON-LD giver mulighed for universel identifikation af JSON-objekter, hvorved et JSON-dokument kan henvise til et objekt, der er beskrevet i et andet JSON-dokument et andet sted på internettet. Syntaksen kan ligeledes håndtere datatype og sprog. JSON-LD giver også mulighed for at serialisere RDF-datasæt ved at bruge nøgleordet @graph.
Følgende JSON-LD-eksempel indkoder grafen i fig. 4:
01 { 02 "@context": "example-context.json", 03 "@id": "http://example.org/bob#me", 04 "@type": "Person", 05 "birthdate": "1990-07-04", 06 "knows": "http://example.org/alice#me", 07 "interest": { 08 "@id": "http://www.wikidata.org/entity/Q12418", 09 "title": "Mona Lisa", 10 "subject_of": "http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619", 11 "creator": "http://dbpedia.org/resource/Leonardo_da_Vinci" 12 } 13 }
Nøgleordet @context i
linje 2 peger på et JSON-dokument, der beskriver, hvordan dokumentet kan mappes
til en RDF-graf (se nedenunder). Hvert JSON-objekt svarer til en RDF-ressource.
I dette eksempel er hovedressourcen http://example.org/bob#me,
som det fremgår af linje 3 ved brugen af nøgleordet @id. Når nøgleordet @id bruges som nøgle i et
JSON-LD-dokument, peger det på en IRI, der identificerer den ressource, der
svarer til det aktuelle JSON-objekt. Ressourcens type beskrives i linje 4, dens
fødselsdato i linje 5 og en af dens venner i linje 6. Linje 7-12 beskriver en
af dens interesser, maleriet af Mona Lisa.
Der oprettes et nyt JSON-objekt i linje 7 til at beskrive dette maleri, og i linje 8 forbindes det med Mona Lisa-IRI’en i Wikidata. Derpå beskrives forskellige egenskaber ved maleriet i linje 9-11.
Den anvendte JSON-LD-kontekst i eksemplet er vist nedenfor.
01 { 02 "@context": { 03 "foaf": "http://xmlns.com/foaf/0.1/", 04 "Person": "foaf:Person", 05 "interest": "foaf:topic_interest", 06 "knows": { 07 "@id": "foaf:knows", 08 "@type": "@id" 09 }, 10 "birthdate": { 11 "@id": "http://schema.org/birthDate", 12 "@type": "http://www.w3.org/2001/XMLSchema#date" 13 }, 14 "dcterms": "http://purl.org/dc/terms/", 15 "title": "dcterms:title", 16 "creator": { 17 "@id": "dcterms:creator", 18 "@type": "@id" 19 }, 20 "subject_of": { 21 "@reverse": "dcterms:subject", 22 "@type": "@id" 23 } 24 } 25 }
Denne kontekst beskriver, hvordan et JSON-LD-dokument kan mappes som en
RDF-graf. Linje 4-9 angiver, hvordan man forbinder Person, interest og knows
til typer og egenskaber i navneområdet FOAF, der er defineret i linje 3. I
linje 8 angives der, at nøgleordet knows
har en værdi, der vil blive tolket som en IRI ved brug af nøgleordene @type og @id.
I linje 10-12 forbindes birthdate
til en egenskabs-IRI i schema.org og angiver, at dens værdi kan forbindes med
datatypen xsd:date.
Linje 14-23 beskriver, hvordan title,
creator og subject_of mappes til egenskabs-IRI’er i
Dublin Core. Når man støder på "subject_of":
"x" i et JSON-LD-dokument, der bruger denne kontekst,
bruges nøgleordet @reverse
(linje 21) til at angive, at det bør mappes til en RDF-tripel, der har
subjektet x IRI, egenskaben dcterms:subject, og hvis objekt er den
ressource, der svarer til det oprindelige JSON-objekt.
RDFa [RDFA-PRIMER] er en RDF-syntaks, der kan brugs til at indlejre RDF-data i HTML- og XML-dokumenter. Dette muliggør, at f.eks. søgemaskiner kan indsamle disse data, når de søger på internettet, og bruge dem til at berige resultaterne (se f.eks. schema.org og Rich Snippets).
Nedenstående HTML-eksempel indkoder RDF-grafen i fig. 4:
01 <body prefix="foaf: http://xmlns.com/foaf/0.1/ 02 schema: http://schema.org/ 03 dcterms: http://purl.org/dc/terms/"> 04 <div resource="http://example.org/bob#me" typeof="foaf:Person"> 05 <p> 06 Bob knows <a property="foaf:knows" href="http://example.org/alice#me">Alice</a> 07 and was born on the <time property="schema:birthDate" datatype="xsd:date">1990-07-04</time>. 08 </p> 09 <p> 10 Bob is interested in <span property="foaf:topic_interest" 11 resource="http://www.wikidata.org/entity/Q12418">the Mona Lisa</span>. 12 </p> 13 </div> 14 <div resource="http://www.wikidata.org/entity/Q12418"> 15 <p> 16 The <span property="dcterms:title">Mona Lisa</span> was painted by 17 <a property="dcterms:creator" href="http://dbpedia.org/resource/Leonardo_da_Vinci">Leonardo da Vinci</a> 18 and is the subject of the video 19 <a href="http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619">'La Joconde à Washington'</a>. 20 </p> 21 </div> 22 <div resource="http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619"> 23 <link property="dcterms:subject" href="http://www.wikidata.org/entity/Q12418"/> 24 </div> 25 </body>
Ovenstående eksempel indeholder fire specielle RDFa-attributter, der gør det
muligt at specificere RDF-tripler i HTML: resource,
property, typeof og prefix.
Atributten prefix i linje
1 angiver IRI-forkortelsen på samme måde som præfikser i Turtle. Lige disse
præfikser kunne strengt taget have været udeladt, eftersom RDFa indeholder en
liste over fordefinerede
præfikser, der omfatter dem, som bruges i dette eksempel.
Elementet div i linje 4
og 14 har attributten ressource,
der angiver den IRI, om hvilken der kan indlejres RDF-udsagn i dette
HTML-element. Meningen med attributten typeof
i linje 4 svarer til forkortelsen (is) a
i Turtle: subjektet http://example.org/bob#me
er en forekomst (rdf:type)
af klassen foaf:Person.
I linje 6 ses attributten property.
Værdien af denne attribut (foaf:knows)
tolkes som en RDF-egenskab i en IRI. Værdien af attributten href (http://example.org/alice#me)
tolkes her som triplens objekt. Derfor er følgende RDF-udsagn resultatet af
linje 6:
<http://example.org/bob#me> <http://xmlns.com/foaf/0.1/knows> <http://example.org/alice#me> .I linje 7 er der en tripel med en literal værdi som objekt. Attributten property angives her som HTML-elementet time. HTML kræver, at indholdet af dette
element skal være et gyldigt tidsformat.
Ved at udnytte HTML’s indbyggede semantik for elementet time, kan RDFa fortolke værdien som xsd:date uden at angive en eksplicit
datatype.
I linjerne 10-11 kan det ses, at attributten resource også bruges til at angive en tripels objekt.
Denne metode bruges, når objektet er en IRI, og når IRI’en selv ikke er en del
af HTML-indholdet (f.eks. attributten href).
Linje 16 viser et andet eksempel på en literal ("Mona Lisa"), der her
er defineret som indhold i attributten span.
Hvis RDFa ikke kan udlede literalens datatype, antages det, at datatypen er xsd:string.
Det er ikke altid muligt at definere RDF-udsagn som del af dokumentets
HTML-indhold. I det tilfælde er det muligt at bruge HTML-begreber, der ikke
specificerer en tripel ud fra indholdet. Et eksempel kan være linjerne 22-23.
HTML-elementet link i linje
23 bruges her til at angive, hvad subjektet er i Europeana-videoen (line 22).
Brugen af RDFa i dette eksempel er begrænset til RDFa Lite [RDFA-LITE]. Yderligere oplysninger om RDFa findes i RDFa Primer [RDFA-PRIMER].
RDF/XML [RDF-SYNTAX-GRAMMAR] gør det muligt at bruge XML-syntaks til RDF-grafer. Da RDF oprindeligt blev udviklet sidst i 1990’erne, var dette den eneste syntaks, og nogen kalder stadig denne syntaks ”RDF”. I 2001 blev der udviklet en forløber til Turtle kaldet ”N3”, og gradvist er de øvrige sprog, der er anført her, taget i brug og er blevet standardiserede.
RDF/XML-eksemplet nedenfor indkoder den RDF-graf, der er afbildet i fig. 4:
01 <?xml version="1.0" encoding="utf-8"?> 02 <rdf:RDF 03 xmlns:dcterms="http://purl.org/dc/terms/" 04 xmlns:foaf="http://xmlns.com/foaf/0.1/" 05 xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" 06 xmlns:schema="http://schema.org/"> 07 <rdf:Description rdf:about="http://example.org/bob#me"> 08 <rdf:type rdf:resource="http://xmlns.com/foaf/0.1/Person"/> 09 <schema:birthDate rdf:datatype="http://www.w3.org/2001/XMLSchema#date">1990-07-04</schema:birthDate> 10 <foaf:knows rdf:resource="http://example.org/alice#me"/> 11 <foaf:topic_interest rdf:resource="http://www.wikidata.org/entity/Q12418"/> 12 </rdf:Description> 13 <rdf:Description rdf:about="http://www.wikidata.org/entity/Q12418"> 14 <dcterms:title>Mona Lisa</dcterms:title> 15 <dcterms:creator rdf:resource="http://dbpedia.org/resource/Leonardo_da_Vinci"/> 16 </rdf:Description> 17 <rdf:Description rdf:about="http://data.europeana.eu/item/04802/243FA8618938F4117025F17A8B813C5F9AA4D619"> 18 <dcterms:subject rdf:resource="http://www.wikidata.org/entity/Q12418"/> 19 </rdf:Description> 20 </rdf:RDF>
I RDF/XML RDF angives tripler i XML-elementet rdf:RDF (linje 2 og 20). Attributterne for elementets
startmærke (linje 3-6) er en forkortet måde at skrive navne på XML-elementer og
attributter. XML-elementet rdf:Description
(kort for http://www.w3.org/1999/02/22-rdf-syntax-ns#Description)
bruges til at definere tripelsæt, hvis subjekt er den IRI, som er angivet af
attributten about. Den
første beskrivelsesblok (linje 7-12) har fire underelementer. Navnet på
underelementet er en IRI, der repræsenterer en RDF-egenskab, f.eks. rdf:type (linje 8). Her repræsenterer
hvert underelement én tripel. I tilfælde, hvor en tripels objekt også er en
IRI, er der intet indhold i egenskabs-underelementet, og objekt-IRI’en angives
ved hjælp af attributten rdf:resource
(linje 8, 10-11, 15 og 18). Linje 10 svarer f.eks. til triplen:
<http://example.org/bob#me> <http://xmlns.com/foaf/0.1/knows> <http://example.org/alice#me> .Når en tripels objekt er en literal, angives literalens værdi som indhold af
egenskabselementet (linje 9 og 14). Datatypen angives som attribut til
egenskabselementet (linje 9). Hvis datatypen er udeladt (linje 14), og der ikke
er noget sprogmærke, antages det, at literalen har datatypen xsd:string.
Eksemplet viser den grundlæggende syntaks. En mere indgående omtale af syntaksen findes i RDF/XML-dokumentet [RDF11-XML]. Det kan virke sært, at attributternes værdier indeholder komplette IRI’er, på trods af at der er defineret præfikser til nogle af disse navneområder. Det skyldes, at disse præfikser kun kan bruges til navne på XML-elementer og attributter.
Det overordnede formål med RDF er at kunne flette meningsfulde informationer fra flere kilder sammen automatisk og danne en større brugbar samling, der stadig giver mening. Som udgangspunkt for denne sammenfletning udtrykkes alle informationer i den samme simple stil som beskrevet ovenfor – i tripler med subjekt-prædikat-objekt. Men der er brug for mere end standardsyntaks, hvis informationerne skal vedblive med at være sammenhængende. Der skal også være enighed om semantikken for disse tripler.
På nuværende tidspunkt i denne introduktion har læseren sandsynligvis opnået en intuitiv forståelse for semantikken i RDF:
Disse og andre begreber er angivet med matematisk præcision i dokumentet om RDF-semantik [RDF11-MT].
En af fordelene ved RDF’s erklærende semantik er, at systemer kan drage logiske følgeslutninger. Hvis systemerne accepterer, at et bestemt sæt tripler i inputtet er sandt, kan de under visse omstændigheder udlede, at også andre tripler må være sande i en logisk forstand. Man siger, at det første sæt tripler er en ”følgerelation” for de følgende tripler. Disse systemer, kaldet ”ræsonneringsprogrammer”, kan indimellem også udlede, at de givne tripler i inputtet modsiger hinanden.
Med RDF’s fleksibilitet, hvor nye vokabularier kan oprettes, når man ønsker at bruge nye begreber, kan man ræsonnere på mange forskellige måder. Når en bestemt slags ræsonnement forekommer nyttig til mange forskellige formål, kan den dokumenteres som et bevissystem. Der er specificeret adskillige bevissystemer i RDF-semantikken. En teknisk beskrivelse af andre bevissystemer, og hvordan man bruger dem sammen med SPARQL, findes i [SPARQL11-ENTAILMENT]. Bemærk, at visse følgerelationer er ret nemme at implementere, og ræsonnementet kan foretages hurtigt, mens andre kræver avancerede teknikker, hvis de skal implementeres effektivt.
Følgende to udsagn kan tjene som eksempel på en følgerelation:
ex:bob foaf:knows ex:alice . foaf:knows rdfs:domain foaf:Person .
Ifølge RDF-semantikken er det logisk at udlede følgende tripel fra denne graf:
ex:bob rdf:type foaf:Person .Ovenstående udledning er et eksempel på en følgerelation i RDF Schema[RDF11-MT].
RDF-semantikken angiver også, at triplen:
ex:bob ex:age "forty"^^xsd:integer .
fører til en logisk uoverensstemmelse, fordi literalen ikke kan acceptere de begrænsninger, der er defineret for datatypen integer i XML Schema.
Bemærk, at værktøjer i RDF måske ikke genkender alle datatyper. Det kræves af værktøjer at de som minimum understøtter datatyperne for strengliteraler og literaler med sprogmærke.
I modsætning til mange andre datamodelleringssprog giver RDF Schema en betydelig frihed. Den samme enhed kan f.eks. bruges både som en klasse og en egenskab. Der sondres heller ikke skarpt mellem begreberne ”klasser” og "forekomster". Derfor er følgende graf gyldig ifølge RDF’s semantik:
ex:Jumbo rdf:type ex:Elephant . ex:Elephant rdf:type ex:Species .
En elefant kan altså både være en klasse (med Jumbo som et eksempel på en forekomst) og en forekomst (nemlig klassen af dyrearter).
Eksemplerne i dette afsnit er kun tænkt til at give læseren en vis forståelse for, hvad man kan udrette med RDF-semantikken. Se [RDF11-MT] for en komplet beskrivelse.
Med RDF kan man kombinere tripler fra enhver kilde med en graf og behandle den som en lovlig RDF. En stor mængde RDF-data er tilgængelig som Linked Data [LINKED-DATA]. Datasæt bliver publiceret og knyttet til internettet med RDF, og mange af dem kan der søges i med SPARQL [SPARQL11-OVERVIEW]. Eksempler på sådanne datasæt, der har været brugt i ovenstående eksempler, omfatter:
En opdateret liste over datasæt, der er tilgængelige som Linked Data, findes på datahub.io.
En række termer er blevet populære til at registrere sammenkædning mellem
RDF-datakilder. Et eksempel er egenskaben sameAs fra OWL-vokabulariet. Denne egenskab kan bruges til at angive, at
to IRI’er i realiteten peger på den samme ressource. Det er nyttigt, fordi
forskellige udgivere kan bruge forskellige identifikatorer til at betegne den
samme ting. VIAF (se ovenfor) har f.eks. også en IRI, der angiver Leonardo da
Vinci. Vi kan registrere denne oplysning ved hjælp af owl:sameAs:
<http://dbpedia.org/resource/Leonardo_da_Vinci>
owl:sameAs <http://viaf.org/viaf/24604287/> .
Sådanne sammenkædninger kan udbredes af RDF-baseret databehandlingssoftware ved f.eks. at flette eller sammenligne RDF-data i IRI’er, der peger på den samme ressource.
Dette afslutter denne korte introduktion til RDF. Yderligere oplysninger kan findes i henvisningerne. Følgende side er også værd at kigge på: W3C Linked Data page.
Antoine Isaac leverede mange eksempler, herunder de forskellige syntaktiske former. Pierre-Antoine Champin leverede et af JSON-LD-eksemplerne. Andrew Wood tegnede diagrammer. Sandro Hawke skrev første del af afsnittet om RDF-semantikken.
Vi er taknemmelige over kommentarerne fra (i alfabetisk rækkefølge) Gareth Adams, Thomas Baker, Dan Brickley, Pierre-Antoine Champin, Bob DuCharme, Sandro Hawke, Patrick Hayes, Ivan Herman, Kingsley Idehen, Antoine Isaac, Markus Lanthaler og David Wood.
Indledningen af dette dokument indeholder en række sætninger fra 2004-introduktionen [RDF-PRIMER]. Resten af Introduktion til RDF 1.1 er et helt nyt dokument.